3 SECONDS OF CODING

PROMOVIDEO
Article
Introduction
The maritime industry is complex and fast paced. It relies heavily on relations between shipping companies and freight forwarders. Creating quotes and bookings via email or phone calls is outdated and simply just too complicated in current times all ending up in poor customer experience. We were tasked with building a web application that bundles these many tasks related to the maritime sector. Our platform integrates features such as sailing schedule management, real-time booking requests, automated quote handling, and track & trace functionality.
Project & background
Research
Websockets
We wanted to make our dashboard as user-friendly as it can be. So having the values of the amount of pending quotes, etc. and the recent activity update in real-time was a must. Since clients do not want to refresh their webpage every minute. In order to obtain such a real-time connection we will use Websockets.
Websockets are used to build real-time communication between a client using the platform and the server behind it. Normally the connection between browser and server is done by constantly sending HTTP-requests to one another. But if you need something that constantly updates,for example the live scores of a tennis match, you do not want to refresh the webpage all the time. With Websockets the client makes an HTTP-request to the server, the server then accepts this request and converts it to a Websocket-connection. Now as long as the connection is established, both sides of the connection can send messages more efficiently, without needing unnecessary overhead. The connection will stay open until either of the two break it.
While doing research we found two possible alternatives to using Websockets: Long polling and Server-Sent-Events (SSE). All three technologies use HTTP-requests a little bit differently.When using long polling the client sends an HTTP-request to the server but if there is no data to send back, the server keeps the connection alive until there is new data available. When the client receives the response the connection is closed. The client immediately sends another request to maintain the connection. That last step makes it less optimal than Websockets.
SSE on the other hand does maintain the connection. But, as the name suggests, only streams data in one direction. From server to client. While this is easier to implement than Websockets and is easier for the server. It does not quite fit our needs since bidirectional communication is required.
AI Chatbot
After consulting with our client, we came to the conclusion that an AI chatbot would be a nice addition to the project. The chatbot should mainly be useful for our client, which is why he came up with the idea that the chatbot should be able to answer when questions are asked about the latest news from ports and shipping companies so that everyone is aware of what is happening in the world. This way, he can find out which ports or shipping companies are the most interesting to book at that moment.
This is going to require a few things: our client receives one or two documents every week with the latest news from shipping companies. An OCR model that can read the text from these documents. An LLM that summarises the documents
Example of a part of the documents:
The image above is only a fraction of the full document. The full document contains 34 pages. That is a lot of text and on top of that the text is not easily outlined because it uses shapes, images and later in the document even graphs and tables. This makes it extremely difficult to use an AI model that can easily summarize this document.
Optical Character Recognition
First things first, the OCR model. An OCR model is an AI tool that is run on documents (mainly images) and detects text written anywhere on the image. This will be necessary since not all text in this document is written plain text. This is a problem since we need plain text to feed into the LLM’s in the next step.
There are a lot of different OCR models and each one is specialised in different types of text recognition.
Large Language Models
To summarize the text we will need to use a large language model. The model will be fed with relevant text according to the question asked by the client. In current times there are tons of LLM’s available for usage. I decided to make an analysis on 4 different, currently popular, models: GPT-4, Claude 3.5, Meta Llama 3.1 7B and Mistral 7B. We mainly focussed on their speed, cost and intelligence.
Speed
This is the most important factor since we do not want our customers to have to wait long on the response to their question.
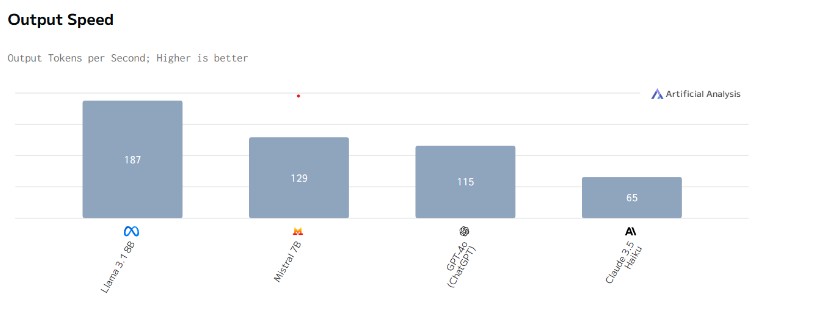
The image above shows the output speed of the different models. Output speed refers to how fast a model generates text, usually measured in tokens per second. The speed depends on a model’s factors like the model size, the hardware it is running and many more. Faster models will generate faster responses but this shows some correlation with the model’s intelligence.
Intelligence
Opposed to speed is the intelligence of a model, another important factor. Larger models will generate more accurate answers. An advanced model can better understand context and thus summarize a better answer.

Here we can indeed see that the previously slower models are almost twice as ‘smart’ as opposed to the faster models.
Cost
Though some are, not all LLM’s are free to use. GPT and Claude cost money to use, which can add up quickly when processing large volumes of data. Paying is not an option for students like us because we work with a limited budget. On the other hand, open-source solutions like Llama and Mistral offer similar services without having to pay.
Conclusion
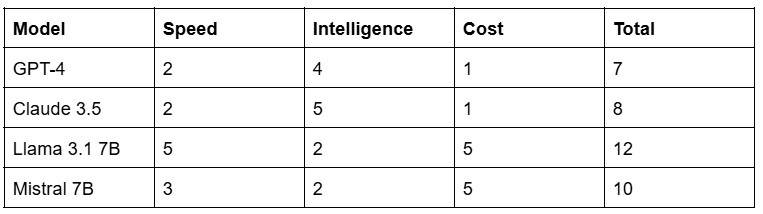
After evaluating all four LLM’s it is clear that the Llama model is most suitable for our needs. It is the fastest model and speed is the attribute we value most. Additionally, cost was a very big factor and Llama being free to use only speaks in its favor. That is why we decided to use the Llama 3.1 8B model. Hereunder is a small analysis showing the differences we found during our research. Higher is better (1–5).
Gemini
Despite our analysis about these four popular LLM’s and getting to work with the Llama model. We found that the response time was not fast enough to our likings due to the model running on our local devices. This made the model less suitable for our needs. We decided to look for yet another popular model. It being Google’s own Gemini model. We quickly noticed that this model was way better than we initially thought. After comparing it to the Llama model we found that it was nearly twice as intelligent.
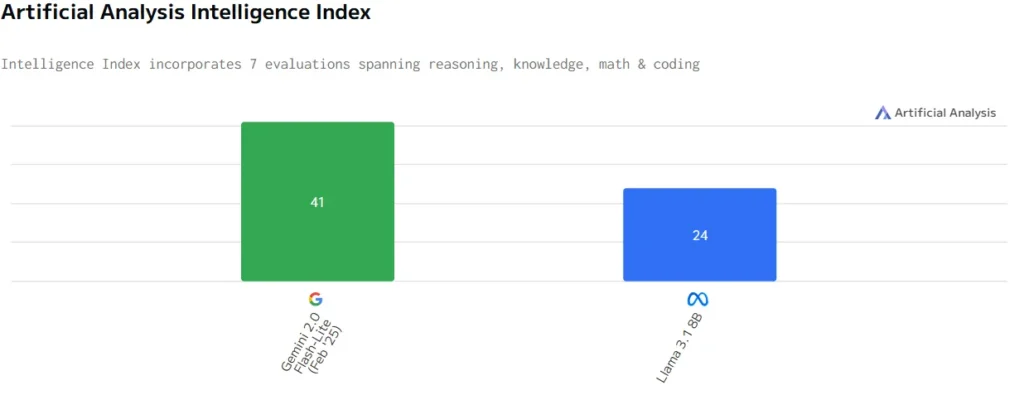
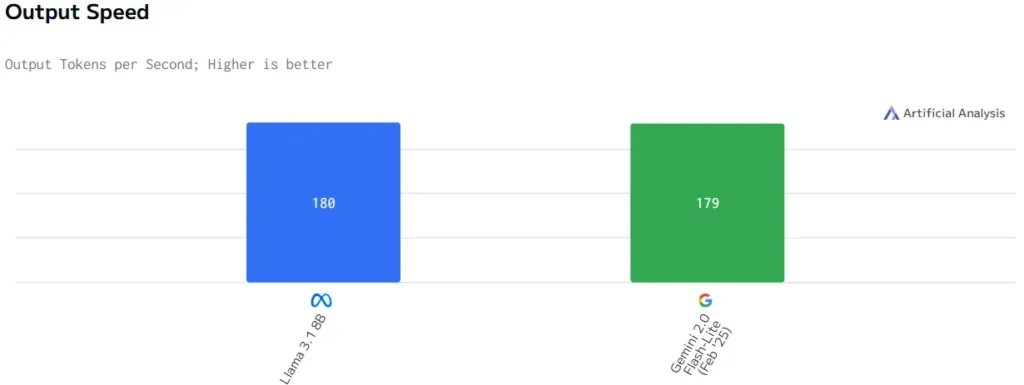
And despite the output speed-graph (below) showing virtually no difference in speed between these two models, after testing we found that the response time of the Llama model stood no match for the model of Gemini. This may be due to the reason that we ran Llama locally while we used Gemini’s API interface to compute answers. Nonetheless, we decided to continue with using the Gemini model due to its performance shown during our tests.
References
Tesseract-Ocr. (n.d.). GitHub — tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository). GitHub. https://github.com/tesseract-ocr/tesseract
spacy-layout · spaCy Universe. (n.d.). Spacy-layout. https://spacy.io/universe/project/spacy-layout
Ollama. (n.d.). Ollama. https://ollama.com/
Google AI for Developers. (n.d.). Gemini Developer API | Gemma open models | Google AI for Developers. https://ai.google.dev/
Mistral AI | Frontier AI in your hands. (n.d.). https://mistral.ai/
Artificial analysis. (n.d.). Artificial Analysis. https://artificialanalysis.ai/